MensaarLecker Development Log (2) -- Web Developing and GitHub Workflow
This blog post is trying to tell you:
- My personal experience when developing a web crawler using Selenium
- Explained with examples from my Repository: MensaarLecker
Fetching Data from Web Development
Previous post: MensaarLecker Development Log (1) – Web Crawling
Continuing from last post, we have already implemented a script that collect the Mensa menu and stored it on Google Sheets. It is time to build our web interface to connect the database.
Fetch Data from Google Sheets using Publish
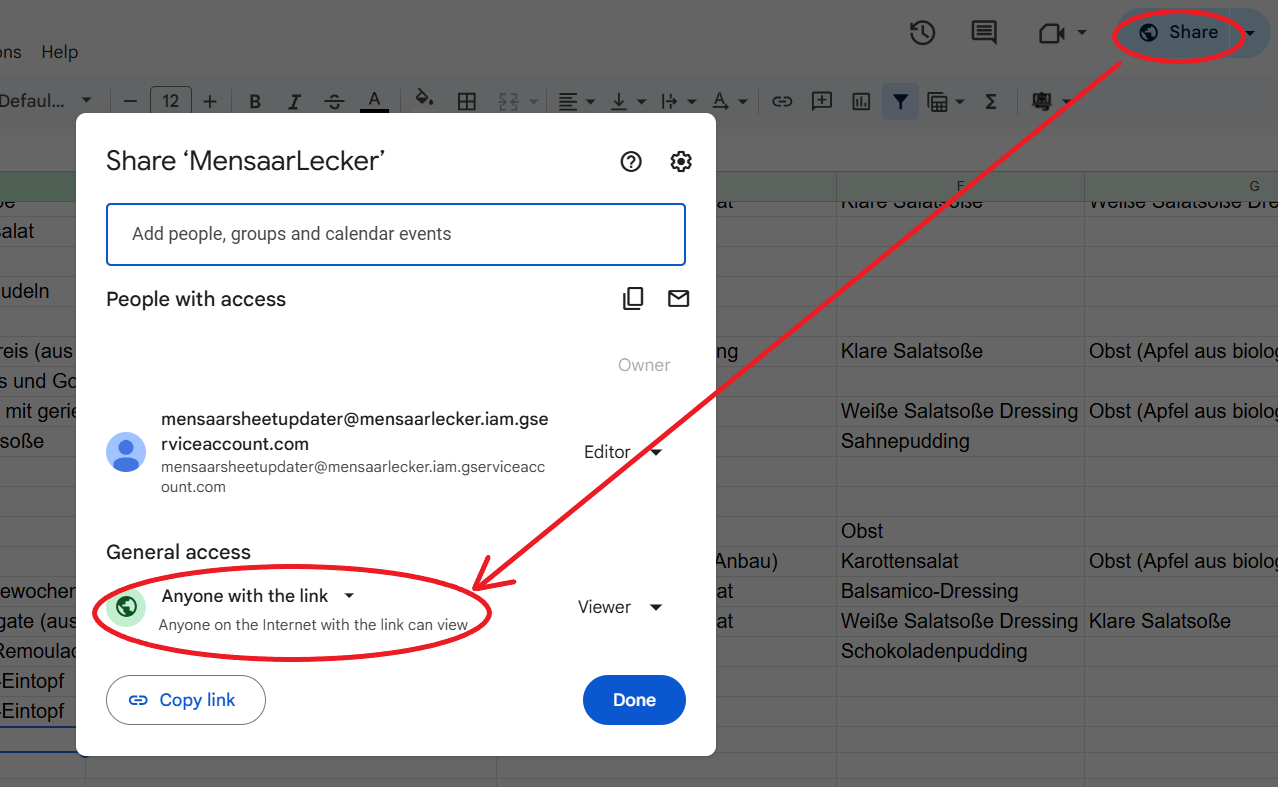
First, we need to publish our spreadsheet so that it is public to fetch the data.
In the Spreadsheet, click Share → Change access to Anyone with the link.
Click File → Share → Publish to the web.
Select Entire Document → Comma-separated values (.csv) and click Publish.
Copy the public CSV link.
1 | |
However, the script return no data, why?
1 | |
CORS Policy and XSS
Cross-origin resource sharing (CORS) is an extension of the same-origin policy. You need it for authorized resource sharing with external third parties. – Amazon Web Services
This is a cyber security scheme to avoid XSS (Cross-site scripting), in a nutshell, when we run the script, the code cannot proceed because it doesn’t login to any Google account! You can imagine the request is block by a imaginary login page and our program doesn’t know how to react.
Second Attempt – Google Apps Script
Google doesn’t allow users to fetch their data casually, except this is executed under Google’s server. This means we need to run our fetching function using Google’s service. Apps Script provide a JavaScript editor to save your code.
1 | |
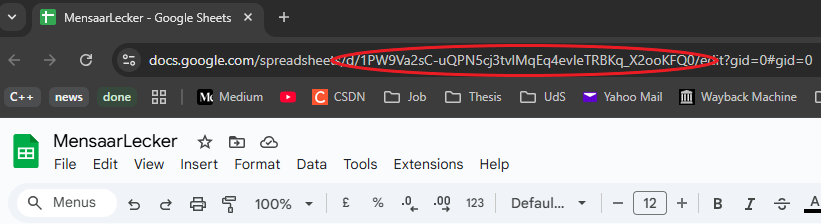
To get the sheet ID, we can simply open the sheet and it is part of the URL:
Deploying the function and fetch the data
Afterwards, we can deploy this function and it will generate a unique URL for the function output and we can fetch the data (here we export the data in json format) and use it in our code.
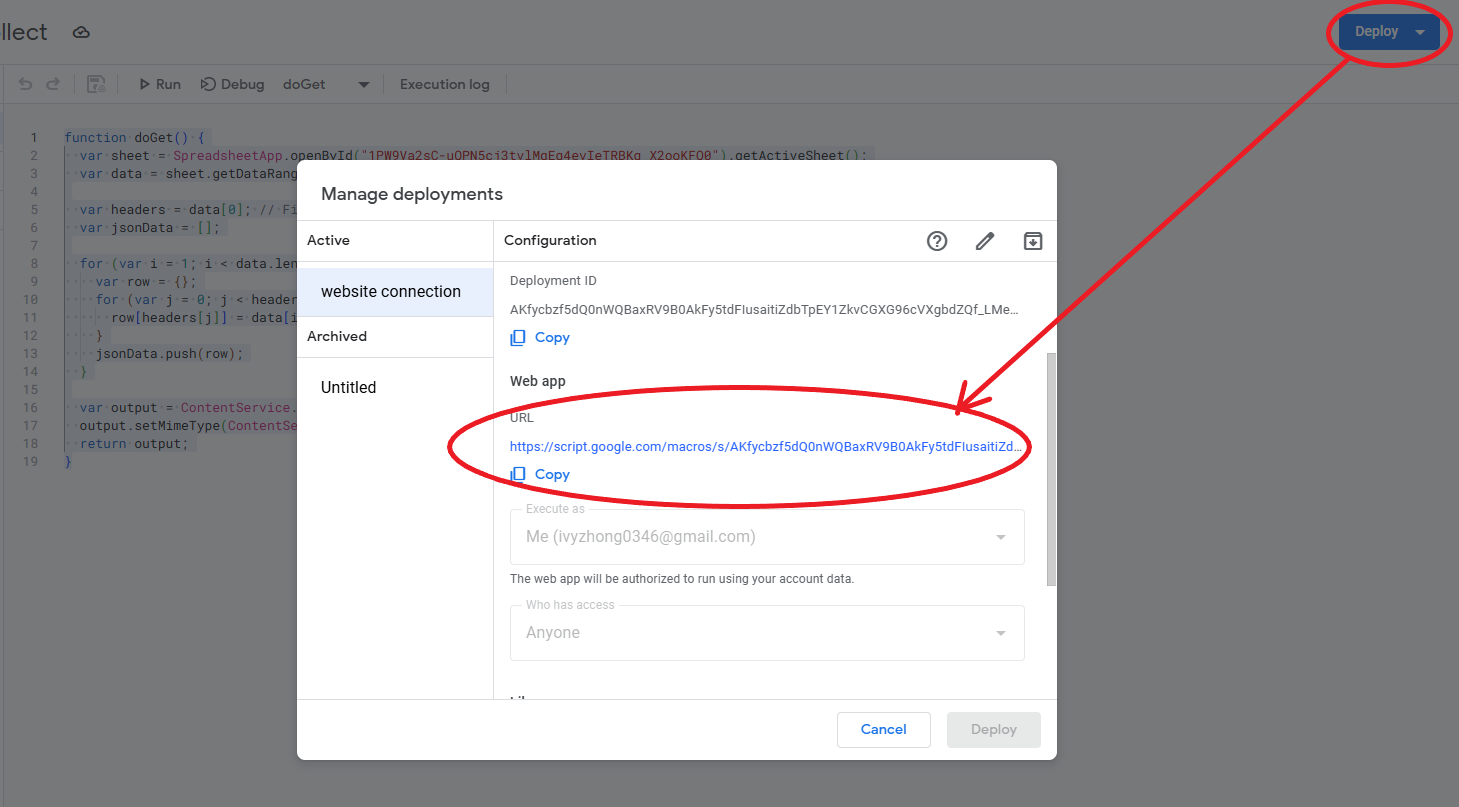
You can also double check the URL and make sure it does return the value correctly → link
1 | |
Webpage Implementation
To simplify our automation process on GitHub, we will continue implement our HTML code using Python. Our website should have two pages: index.html contains today’s menu, and menu.html contains the history of collected menus.
Static data – Tripe Quotes
We can put all the static code in strings. In Python we can store multi-line strings using triple quotes.
1 | |
Enhance the design using DataTable
Since we will collect the menu everyday, the table in menu.html will become too long for loading and hard to check. We can use DataTable that provide basic table layout like filtering, searching, and sorting. Also, it is very easy to implement, simply include the JavaScript and CSS link in the HTML code and you can get the basic, but decent design.
Automation with GitHub Workflow
Finally, after we deployed the code to GitHub, remember our original goal:
Scrape the Mensa menu every weekday and store it to Google Sheets
Fetch the Data Collection from Google Sheets and update the website
In fact, we can run the python script periodically using Github workflow, here are the steps:
The workflow has to be implemented in
.ymlformat, and stored in.github/workflows/{workflow_name}.ymlBefore running the python script, make sure python is set with all the dependencies installed:
1 | |
- For the full workflow, you can find the skeleton code template on GitHub or you can check here.
A random summary
With all these works, we managed to build our web crawler and a static website using only python. And Github workflow can help us with daily updates.
Continue Reading: MensaarLecker Development Log (3) – Telegram Bot Deployment and Integration
MensaarLecker Development Log (2) -- Web Developing and GitHub Workflow


