Repository: MensaarLecker
Motivation
Me and my friends hatelove the UdS Mensa so much! The infinite frozen food and french fries menus give us so much energy and motivation for the 5-hour afternoon coding marathon. However, no one actually knows how many potatoes they have exterminated throughout the week. We have a genius webpage created by some Schnitzel lover. Personally, I like its minimalistic layout and determination on Schnitzel searching.
However, we want more.
It’s not just Schnitzel; we want to know everything about their menu. We want to know what’s inside the mensa ladies’ brains when they design next week’s menu.
The desire never ends. We need more data, more details, more, More, MORE!
Developing Process
Our Goal here is simple:
Scrape the Mensa menu every weekday and store it to Google Sheets
Fetch the Data Collection from Google Sheets and update the website
Web Scraping
To collect the data, we can use Python libraries to simplfied the process. But the basic idea it the same: we try to find the pattern of the HTML tag and locate the desired data.
Beautiful Soup
I started my journey with Beautiful Soup, one of the most popular Python web scraper packages. However, as a Uni that is well-known for its computer science program, all the menus are rendered using JavaScript. And beautiful can only scrape HTML and XML tags. So the scraper can only see an empty skeleton page:
![]()
Selenium
Basically, Selenium is a Webdriver that opens a browser naturally, like a human user. Then from there we can scrape the rendered information. Things get simpler once we can see the website as we see it on the browser. We just need to find the tag that contains the information we need and save it for storage.
Desired Data and Tags
| Data | Tag |
|---|---|
| menus | <div class="counter"> |
| date | <div class="cursor-pointer active list-group-item"> |
| main dish | <span class="meal-title"> |
| side dish | <div class="component"> |
The first part of the task is to get the daily menu. We also get the date on the website to make the following work easier.
By the find_element and find_elements functions in Selenium, we can create a simple scraper like this:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
driver.get("https://mensaar.de/#/menu/sb")
counters = driver.find_elements(By.CLASS_NAME, "counter")
for counter in counters:
meal_title = meal.find_element(By.CLASS_NAME, "meal-title").text.strip()
However, on the webpage there is also a counter called Wahlessen. Which refers to a more pricy and unpredictable menu, and we want to exclude its data:
counter_title = counter.find_element(By.CLASS_NAME, "counter-title").text.strip()
# Filter for specified counter titles
if counter_title in ["Menü 1", "Menü 2", "Mensacafé"]:
meal_title = meal.find_element(By.CLASS_NAME, "meal-title").text.strip()
Storage
In order to make the database easy to be accessed by other users/students, we decided to deploy the data set to Google SpreadSheets.
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=2)
print(f"Results saved to {output_file}")
# Save the updated occurrence counts to the JSON file
count_result = {
"meal_counts": dict(meal_count),
"component_counts": dict(component_count)
}
with open(count_file, "w", encoding="utf-8") as f:
json.dump(count_result, f, ensure_ascii=False, indent=2)
print(f"Counts saved to {count_file}")
Change the time format
Once we fetch data, you may notice that the website display the date in german format e.g. “Freitag, 21. März 2025”, which is not recognized by Google Sheets directly. So we need to make a function to convert them before uploading:
GERMAN_MONTHS = {
"Januar": "01", "Februar": "02", "März": "03", "April": "04",
"Mai": "05", "Juni": "06", "Juli": "07", "August": "08",
"September": "09", "Oktober": "10", "November": "11", "Dezember": "12"
}
def format_date(german_date):
match = re.search(r"(\d{1,2})\. (\w+) (\d{4})", german_date)
if match:
day, month, year = match.groups()
month_number = GERMAN_MONTHS.get(month, "00")
return f"{year}-{month_number}-{int(day):02d}"
return "0000-00-00"
Upload the data to Google Sheets
In order to interact with the Google Sheets, we need to use Google API. First, go to Google Cloud Console.
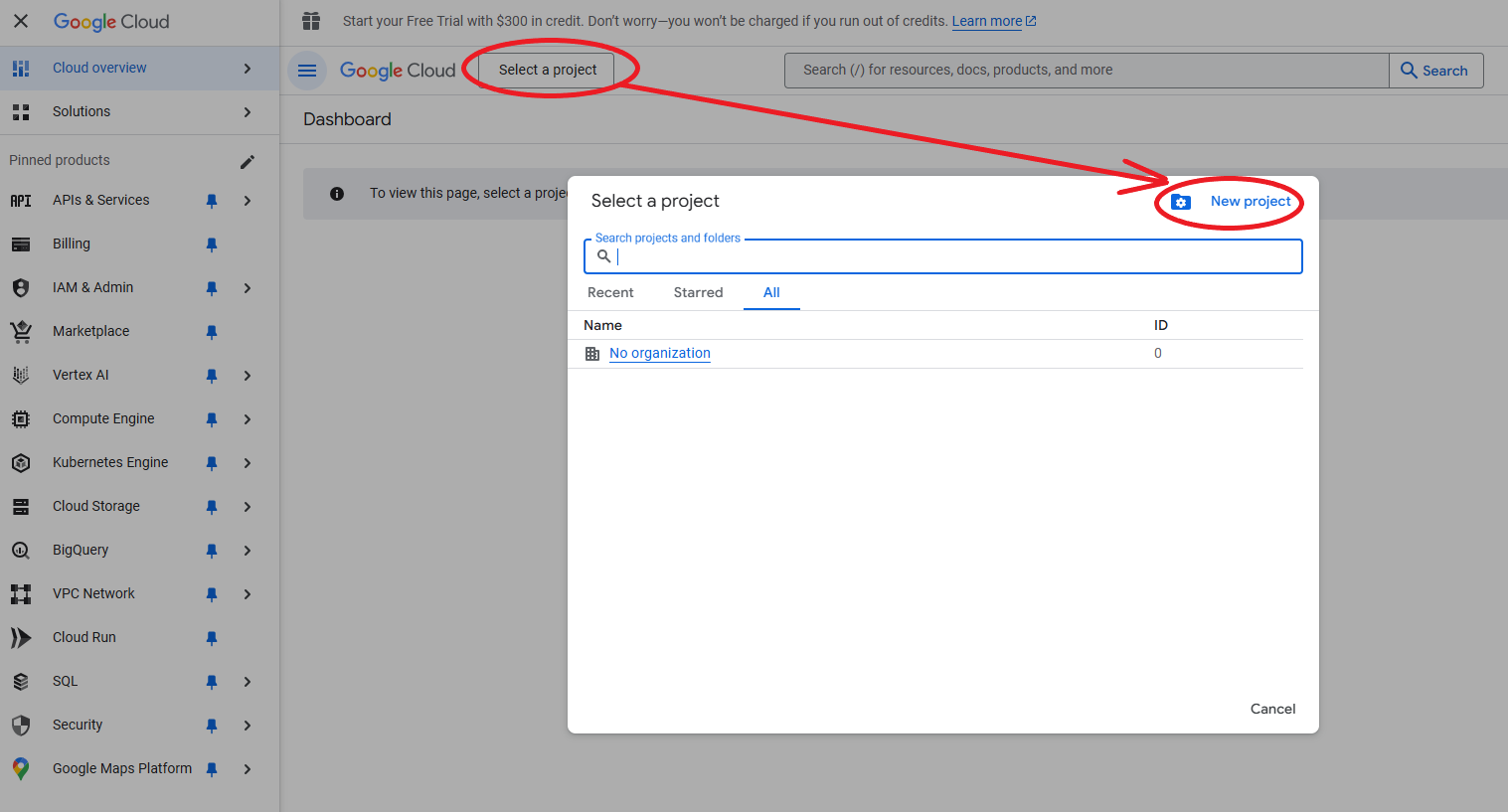
Create a new project. Next, go to API and Services, click Enable API and Services
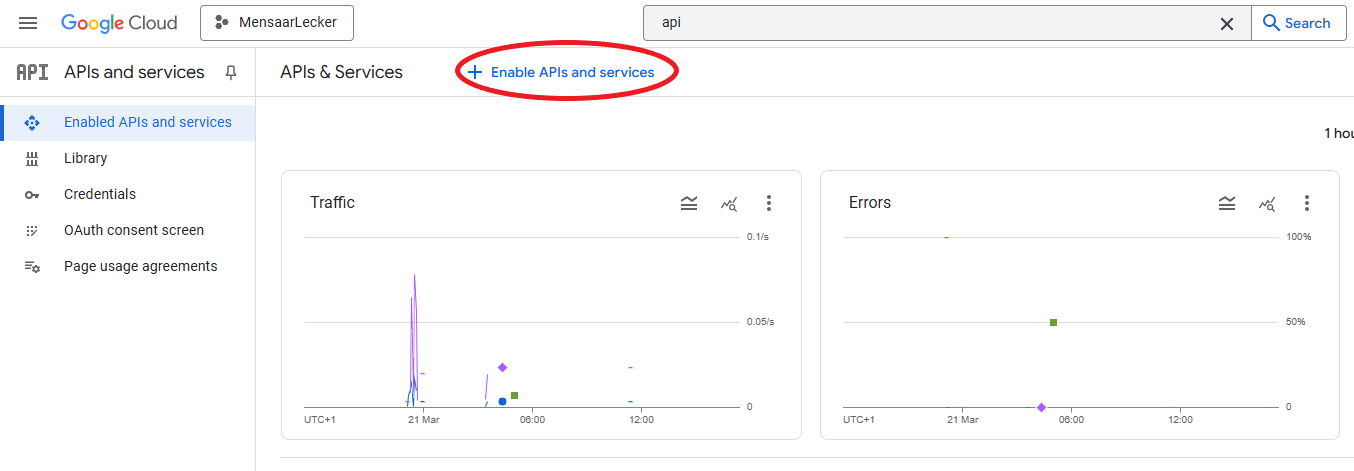
Search Google Sheets API, select it and choose Enable。
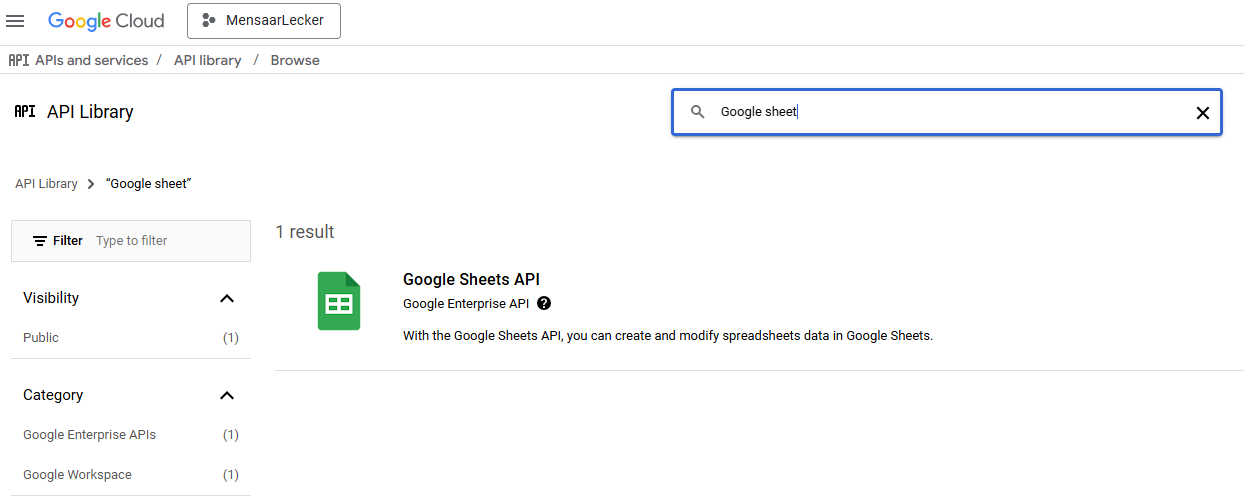
Move Credentials from the sidebar, then choose Create credentials → Create service account
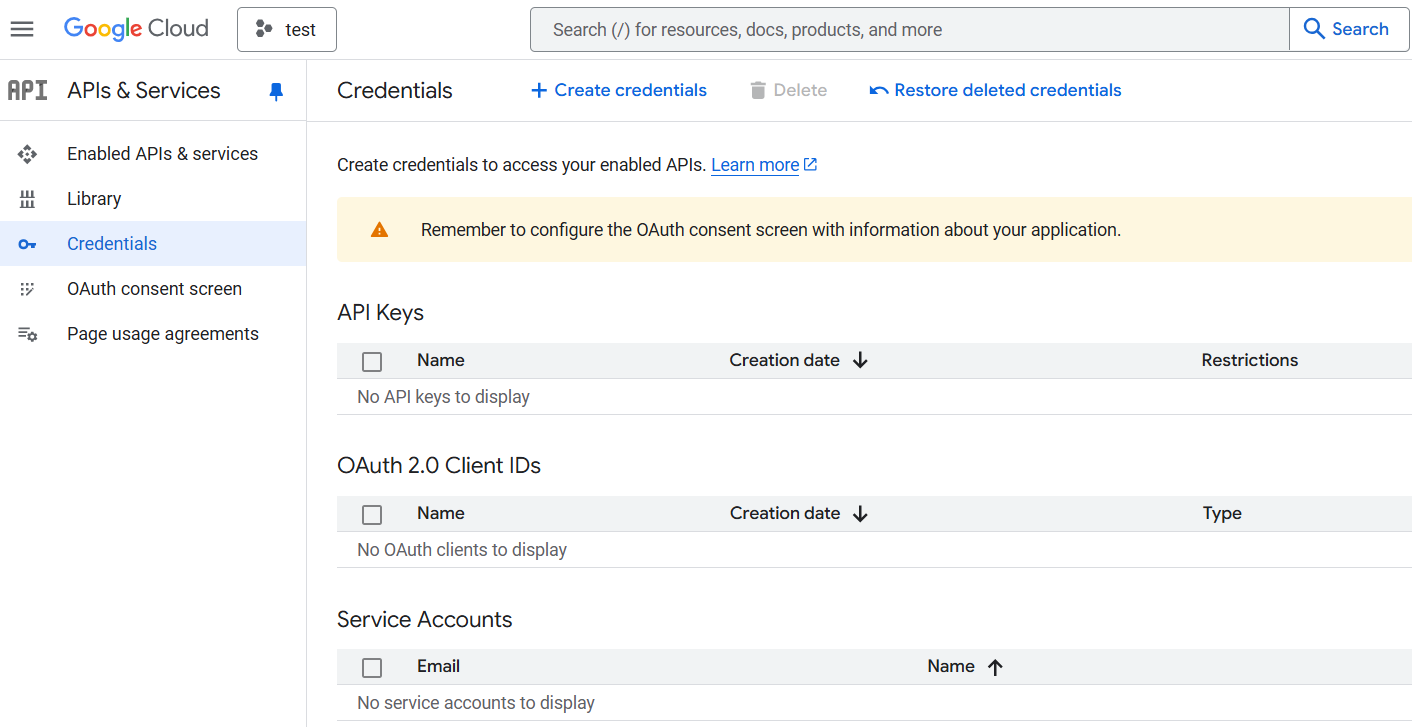
In step 2, choose the role Editor
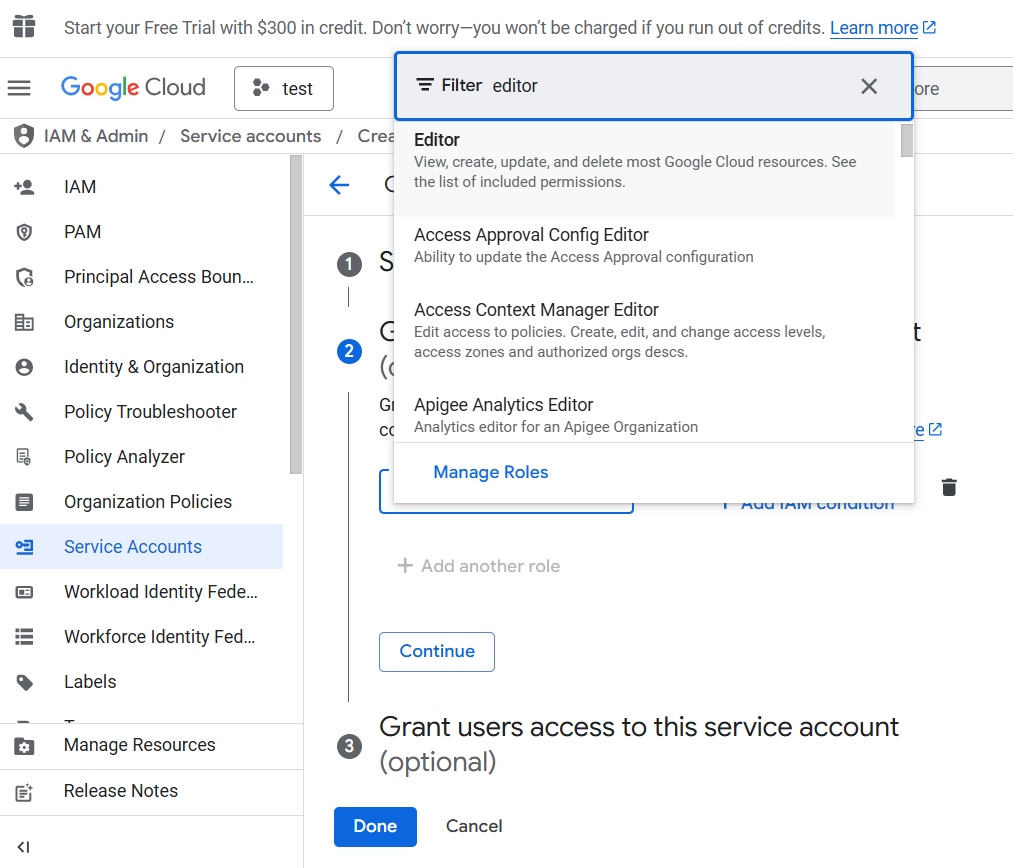
Now, when you come back to the Credentials page, you should see a newly generated email under Service Accounts, click it and select the tab Keys
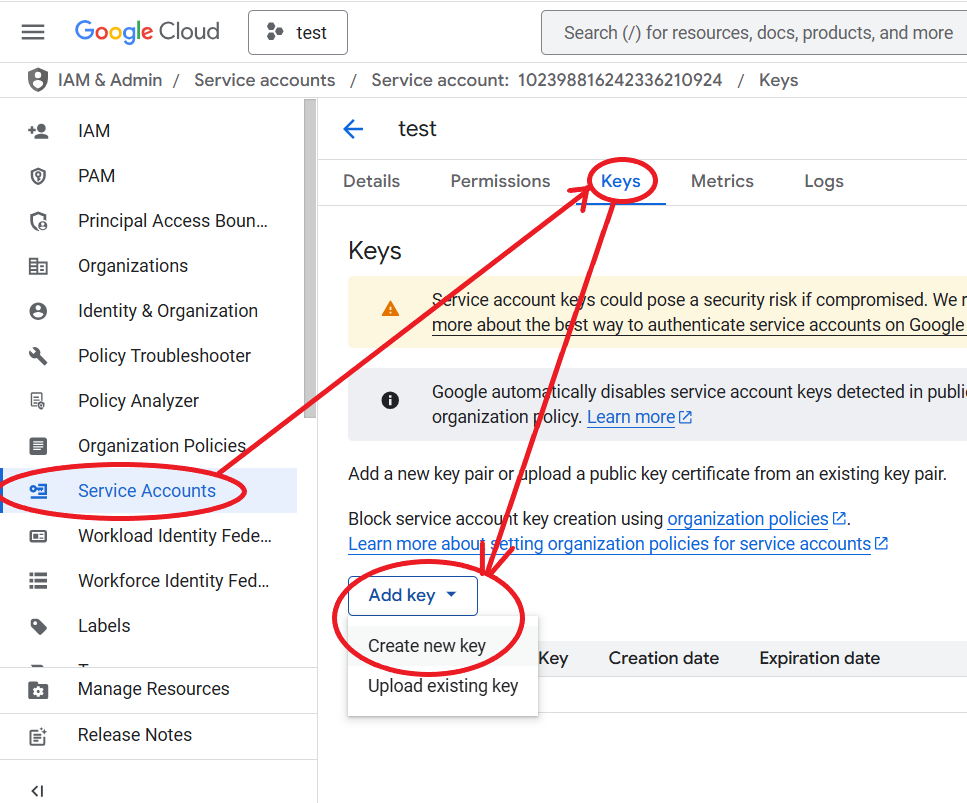
Select Create new key, choose JSON format, the file should start downloading automatically.
Important NoticeThis JSON file contains sensitive data, you should NEVER directly use it in your code, save it as an environment variable or save it as a secret on Github
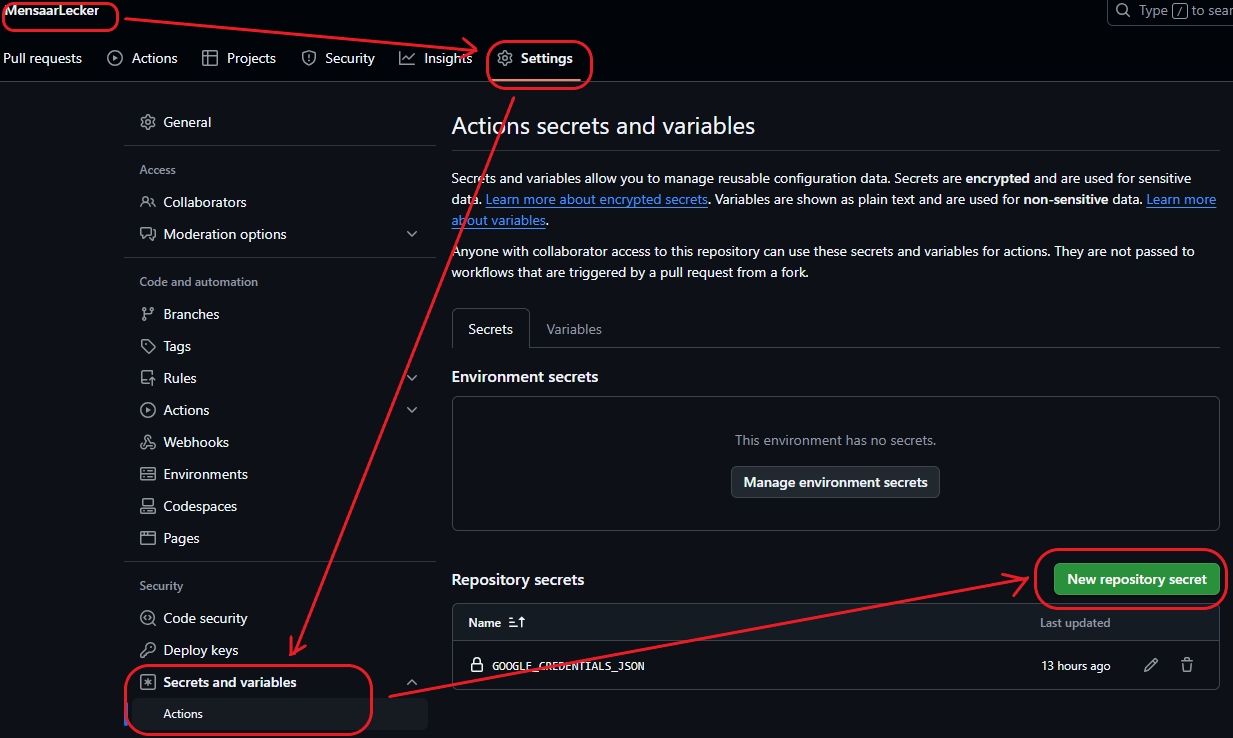
With this key we can login the email we just created in Service Accounts, so that it is treated as a virtual users when running the script. Same as human users, in order to access the sheet we need to add this email as an editor in Google Sheets.
try:
# Read and validate credentials.json before using it
if not os.path.exists("credentials.json"):
print("❌ credentials.json not found!")
return
with open("credentials.json", "r", encoding="utf-8") as f:
raw_creds = f.read()
creds_data = json.loads(raw_creds)
# Save to a temp file just in case gspread needs it as a file
temp_path = "parsed_credentials.json"
with open(temp_path, "w", encoding="utf-8") as f:
json.dump(creds_data, f)
creds = ServiceAccountCredentials.from_json_keyfile_name(temp_path, scope)
client = gspread.authorize(creds)
sheet = client.open(SHEET_NAME).sheet1
print("✅ Google Sheets Auth OK")
End of Scraping
Now we all set! Next, we need to display our collected results on web interfaces.
Continue Reading: MensaarLecker Development Log 2 – Web Developing and GitHub Workflow
Please cite the source for reprints, feel free to verify the sources cited in the article, and point out any errors or lack of clarity of expression. You can comment in the comments section below or email to GreenMeeple@yahoo.com