Repository: MensaarLecker
Motivation
Previous Post: MensaarLecker Development Log 1 – Web Crawling
Me and my friends hatelove the UdS Mensa so much! The infinite frozen food and french fries menus give us so much energy and motivation for the 5-hour afternoon coding marathon. However, no one actually knows how many potatoes they have exterminated throughout the week. We have a genius webpage created by some Schnitzel lover. Personally, I like its minimalistic layout and determination on Schnitzel searching.
However, we want more.
It’s not just Schnitzel; we want to know everything about their menu. We want to know what’s inside the mensa ladies’ brains when they design next week’s menu.
The desire never ends. We need more data, more details, more, More, MORE!
Fetching Data from Web Development
Continuing from last post, we have already implemented a script that collect the Mensa menu and stored it on Google Sheets. It is time to build our web interface to connect the database.
Fetch Data from Google Sheets using Publish
First, we need to publish our spreadsheet so that it is public to fetch the data.
In the Spreadsheet, click Share → Change access to Anyone with the link.
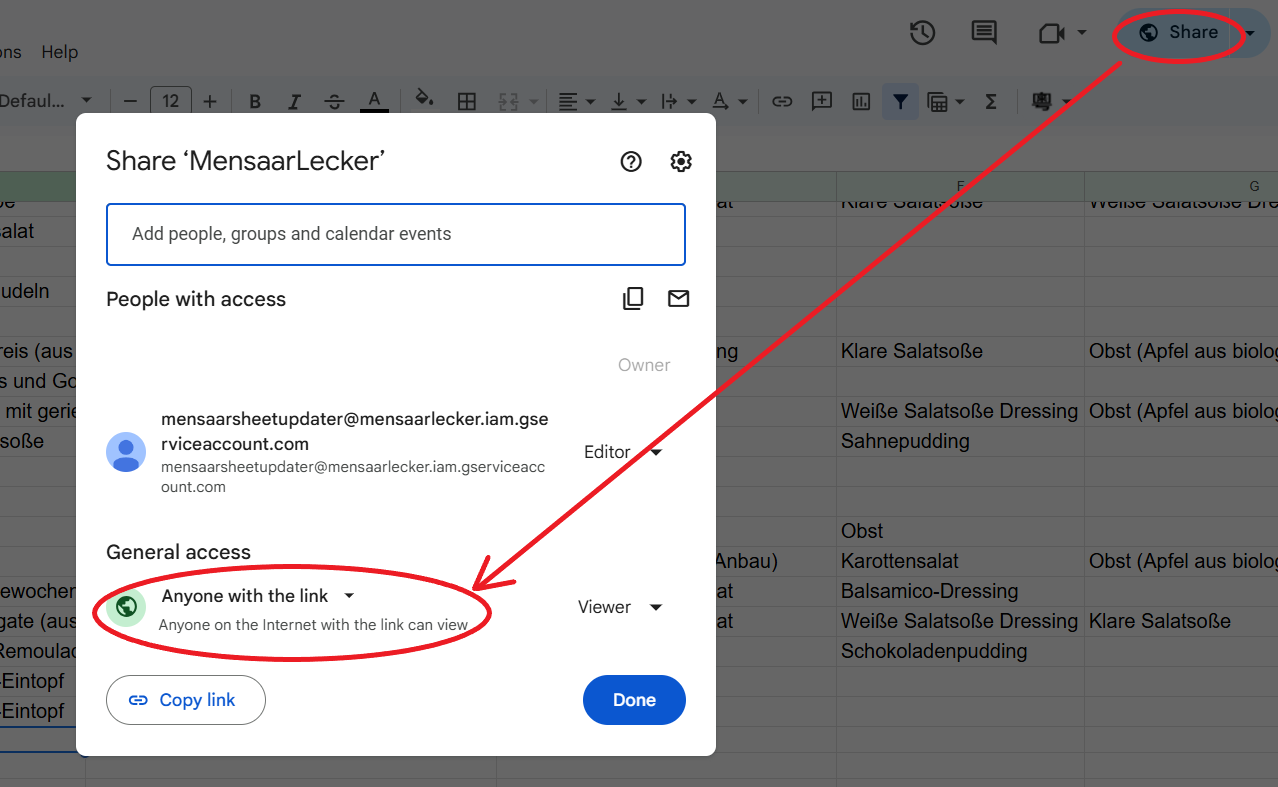
Click File → Share → Publish to the web.
Select Entire Document → Comma-separated values (.csv) and click Publish.
Copy the public CSV link.
SCRIPT_URL = {PUBLISH_LINK}
# Fetch JSON data
def fetch_menu():
try:
response = requests.get(SCRIPT_URL)
response.raise_for_status() # Raise error if bad response
return response.json()
except requests.exceptions.RequestException as e:
print(f"❌ Error fetching menu: {e}")
return []
However, the script return no data, why?
Access to fetch at 'https://docs.google.com/spreadsheets/...' from origin 'null' has been blocked
by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource.
If an opaque response serves your needs, set the request's mode to 'no-cors' to fetch the resource with CORS disabled.
CORS Policy and XSS
Cross-origin resource sharing (CORS) is an extension of the same-origin policy. You need it for authorized resource sharing with external third parties. – Amazon Web Services
This is a cyber security scheme to avoid XSS (Cross-site scripting), in a nutshell, when we run the script, the code cannot proceed because it doesn’t login to any Google account! You can imagine the request is block by a imaginary login page and our program doesn’t know how to react.
Second Attempt – Google Apps Script
Google doesn’t allow users to fetch their data casually, except this is executed under Google’s server. This means we need to run our fetching function using Google’s service. Apps Script provide a JavaScript editor to save your code.
function doGet() {
var sheet = SpreadsheetApp.openById("PUT_YOUR_SHEET_ID_HERE").getActiveSheet();
var data = sheet.getDataRange().getValues();
var headers = data[0];
var jsonData = [];
for (var i = 1; i < data.length; i++) {
var row = {};
for (var j = 0; j < headers.length; j++) {
row[headers[j]] = data[i][j];
}
jsonData.push(row);
}
var output = ContentService.createTextOutput(JSON.stringify(jsonData));
output.setMimeType(ContentService.MimeType.JSON);
return output;
}
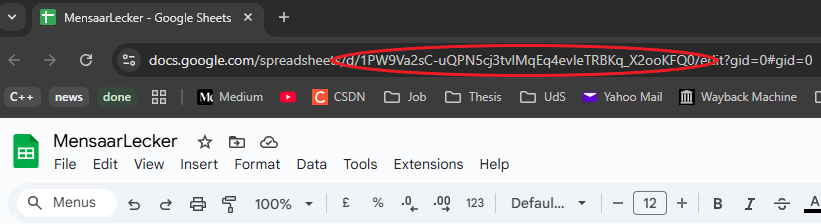
To get the sheet ID, we can simply open the sheet and it is part of the URL:
Deploying the function and fetch the data
Afterwards, we can deploy this function and it will generate a unique URL for the function output and we can fetch the data (here we export the data in json format) and use it in our code.
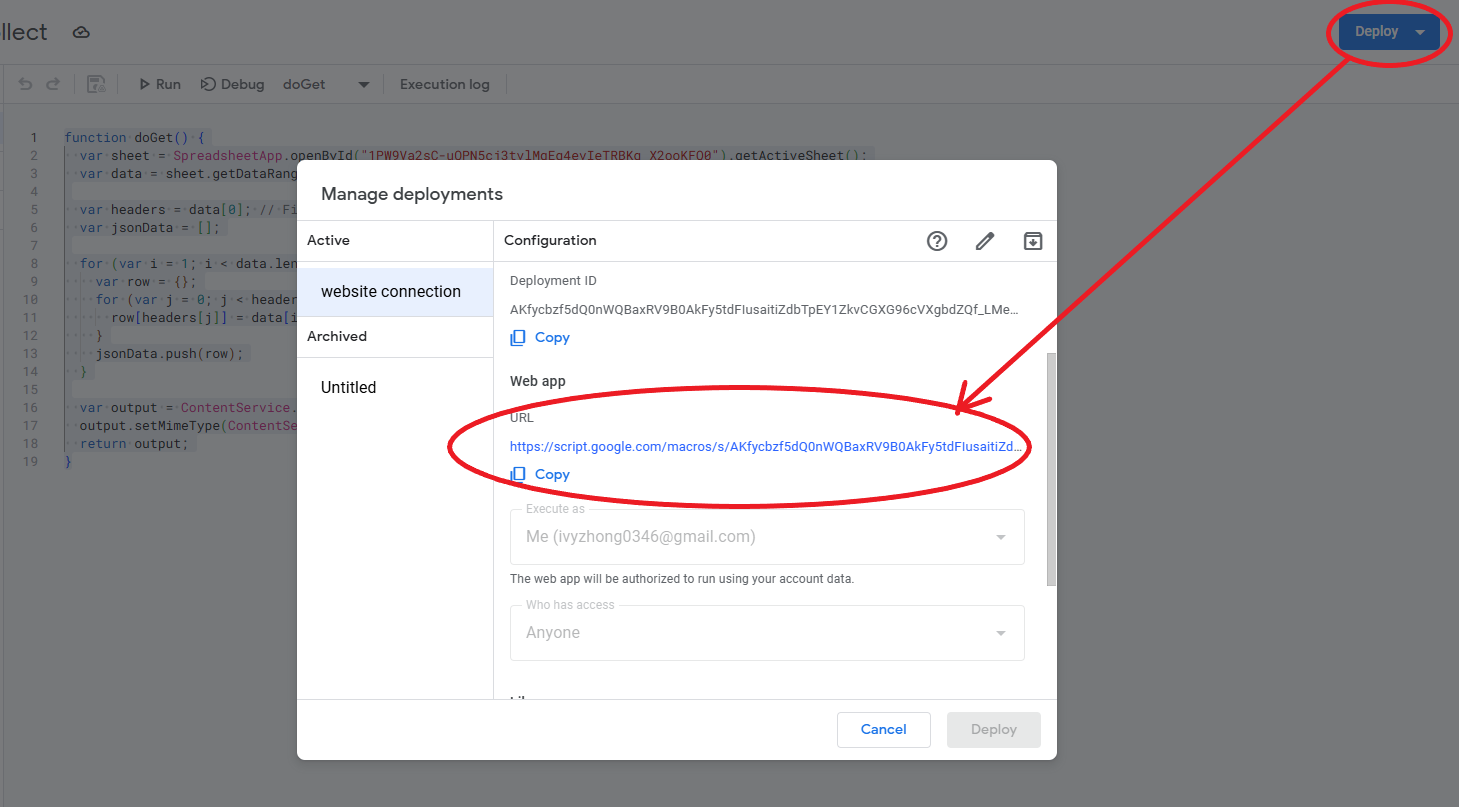
You can also double check the URL and make sure it does return the value correctly → link
SCRIPT_URL = "URL_DEPLOYED_FROM_APP_SCRIPT";
# Fetch JSON data
def fetch_menu():
try:
response = requests.get(SCRIPT_URL)
response.raise_for_status() # Raise error if bad response
return response.json()
except requests.exceptions.RequestException as e:
print(f"❌ Error fetching menu: {e}")
return []
Webpage Implementation
To simplify our automation process on GitHub, we will continue implement our HTML code using Python. Our website should have two pages: index.html contains today’s menu, and menu.html contains the history of collected menus.
Static data – Tripe Quotes
We can put all the static code in strings. In Python we can store multi-line strings using triple quotes.
html = f"""<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Mensaar Today</title>
<style>
body {{ font-family: Arial, sans-serif; padding: 20px; text-align: center; background-image: url('src/uds_spirit.jpg'); }}
h1 {{
background: rgba(255, 255, 255, 0.8);
color: #003C71;
padding: 10px 20px;
display: inline-block;
border-radius: 10px;
box-shadow: 2px 2px 10px rgba(0, 0, 0, 0.2);
}}
.container {{ width: 80%; margin: auto; }}
.closed-message {{ font-size: 26px; color: red; font-weight: bold; padding: 20px; background: #fff3f3; border-radius: 10px; }}
.menu-card {{ background: white; padding: 15px; margin: 10px 0; border-radius: 10px; box-shadow: 2px 2px 10px rgba(0,0,0,0.1); text-align: left; }}
.meal-title {{ font-size: 20px; font-weight: bold; }}
.meal-components {{ font-size: 16px; color: #666; }}
.meal-frequency {{ font-size: 14px; color: #888; font-style: italic; }}
.button {{ padding: 12px 20px; background: #007bff; color: white; border-radius: 5px; text-decoration: none; }}
</style>
</head>
<body>
<h1>Mensaar Menu for {today}</h1></br>
<a href="menu.html" class="button">📜 View Full Menu</a>
<div class="container">
"""
Enhance the design using DataTable
Since we will collect the menu everyday, the table in menu.html will become too long for loading and hard to check. We can use DataTable that provide basic table layout like filtering, searching, and sorting. Also, it is very easy to implement, simply include the JavaScript and CSS link in the HTML code and you can get the basic, but decent design.
Automation with GitHub Workflow
Finally, after we deployed the code to GitHub, remember our original goal:
Scrape the Mensa menu every weekday and store it to Google Sheets
Fetch the Data Collection from Google Sheets and update the website
In fact, we can run the python script periodically using Github workflow, here are the steps:
The workflow has to be implemented in
.ymlformat, and stored in.github/workflows/{workflow_name}.ymlBefore running the python script, make sure python is set with all the dependencies installed:
- name: 🛠 Set up Python uses: actions/setup-python@v4 with: python-version: "3.x" - name: 📦 Install dependencies run: | pip install requests selenium webdriver-manager gspread oauth2client - name: 🚀 Run Mensaar Scraper (update Google Sheets) run: | echo "🧪 Starting Mensaar_scraper..." python Mensaar_scraper.py echo "✅ Scraper completed." - name: 🖼️ Run HTML Generator run: | echo "🧪 Generating index.html & menu.html" python generate_menu.pyFor the full workflow, you can find the skeleton code template on GitHub or you can check here.
Please cite the source for reprints, feel free to verify the sources cited in the article, and point out any errors or lack of clarity of expression. You can comment in the comments section below or email to GreenMeeple@yahoo.com