🍽 🥨 MensaarLecker -- A beloved tool to find out Mensa Ladies' favourite menu using Selenium🥨 🍽
Repository: MensaarLecker
As an UdS Student,
Are you tired of seeing french fries🍟 3 times a week, or wondering when I can have the best pizza 🍕 in the Mensacafe?
MensaarLecker aims to collect all the data from Menu 1, 2, and Mensacafe to trace your favourite, or Mensa Ladies’, favourite menu!
🆕 Updates
05.08 – Telegram Bot @Mensaar_Bot are published.
(See my development blog in here! MensaarLecker Development Log 3 – Telegram Bot Deployment and Integration)
04.21 – HTW menus are now added to the statistics.
🥗 Description
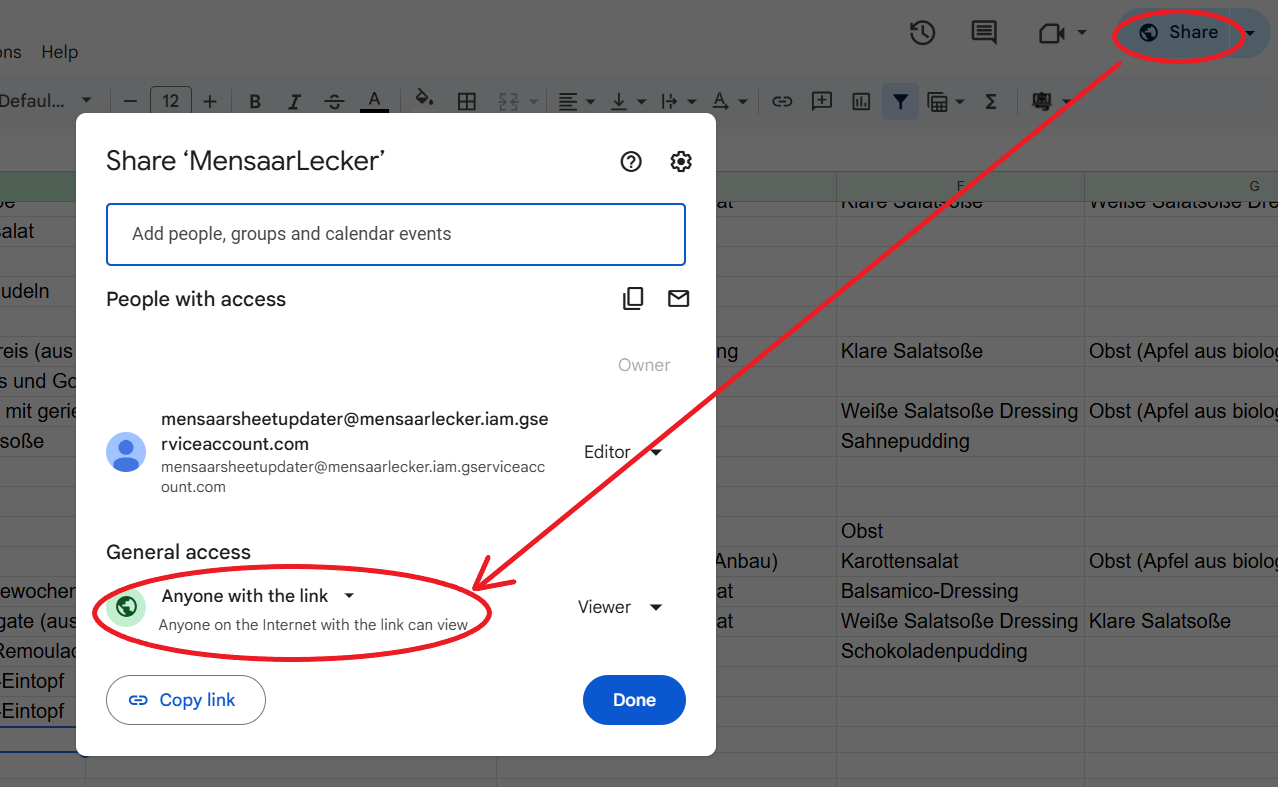
A fully automated scraper and static website for the Saarbrücken Mensa, powered by Python, Selenium, Google Sheets, and GitHub Actions.